This was the first big data project I tackled on my own. I picked Center for Policing Equity challenge on Kaggle for three reasons: I love maps and I love the idea that data scientists can significantly improve our world, in addition to improving the bottom lines of big corporates. And this is exactly the type of messy data one would get in the real world so it was worth thinking about ways to automate the data cleaning process.
…oh yes, and I wanted to play with GeoPandas!
The learning journey had 2 main components: understanding some geospatial principles, and learning some new Python skills to realize my objectives. Here is a summary of what I learned. This post should be read in conjunction with the Kaggle Kernel which contains the actual implementation:

The quest…
“In exchange for unprecedented access to <police> records (such as use of force incidents, vehicle stops, pedestrian stops, calls for service, and crime data), our scientists use advanced analytics to diagnose disparities in policing, shed light on police behavior, and provide actionable recommendations…
Our biggest challenge is automating the combination of police data, census-level data, and other socioeconomic factors. Shapefiles are unusual and messy – which makes it difficult to, for instance, generate maps of police behavior with precinct boundary layers mixed with census layers. Police incident data are also very difficult to normalize and standardize across departments since there are no federal standards for data collection.”
The dataset has a plethora of challenges which could be tackled, but I decided to focus on ways to automate standardizing the geospatial data as much as possible. We have 3 different sources of information for each department (American Community Survey or ACS data from the US Census Bureau, police precinct shapefiles, and “use of force” or UOF data), and if the 3 sources are not aligned we might end up doing the equivalent of superimposing Italy over Texas over Cape Town which would just be nonsensical.
Each police department uses its own standard to collect the data: different types of data are collected, different co-ordinate reference systems (CRS) are used, and in some cases the CRS has not been supplied.
This is a good place to segue into “what on earth are co-ordinate reference systems” (pardon the pun)…
Understanding co-ordinates and projections
We all use GPS tools and so we’re well familiar with latitude and longitude – these are measurements that reference our position on earth in relation to the Greenwich Meridian and the Equator. In South Africa our latitude is always a negative number (we are below the equator therefore negative), and our longitude is always a positive number (we are to the right of the Greenwich Meridian therefore positive).
Latitude and longitude can be thought of as measurements in a 3D space, our actual position on the sphere.
The messy part comes in where we want to draw our earth in a 2D space (e.g. on a flat piece of paper) – in order to represent the earth some compromises need to be made, and these are known as projections. The following picture from earthscience.org shows clearly what I mean by “compromises”:
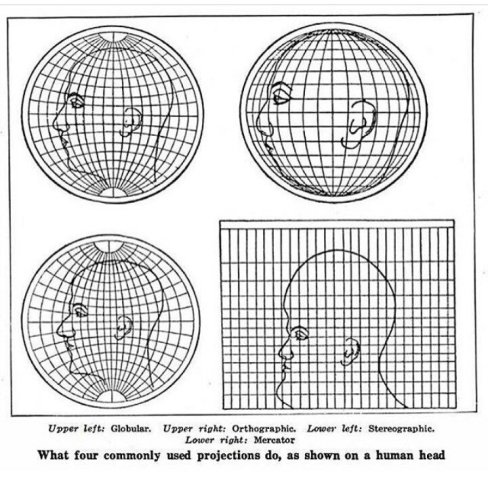
When we work with projections, we no longer use latitude and longitude, we work with Cartesian co-ordinates x, y and z which measure the distance from the centre of the earth (yes, the mid-point inside!) and are therefore given in metres or feet (z, the actual distance to the mid-point, is typically omitted).
Many different projections exist because different regions optimize to best fit their unique requirements and because each projection may prioritize different aspects. Laurette Coetzee’s excellent article on co-ordinates and projections (highly recommended!) explains how airline pilots would want to use a projection where the integrity of distance is preserved, where quantity surveyors might favour a projection where the integrity of area is preserved. This means co-ordinate reference systems, are legion: I used spatialreference.org as my authoritative source and there are literally 1000’s of references.
Understanding shapefiles
Map data typically comes in shapefile format so it’s an important concept to understand. A shapefile is described by Wikipedia as a format which can spatially describe vector features: points, lines, and polygons, representing, for example, water wells, rivers, and lakes. The format is composed of several different files which together hold all the required information to draw these objects. There are 3 mandatory files, without which you will not be able to work: *.shp, *.shx, and *.dbf. However, there is a fourth file *.prj which contains the projection and co-ordinate reference system information. If this file is not supplied you will be able to draw the shapes of states and counties, but you won’t actually know exactly where in the world they are located. The moment you want to combine one dataset with another you may end up superimposing Italy over Texas!
The magic of GeoPandas
I can’t over-state how much I loved working with this library. It is very much like working in regular Pandas so it’s easy to get started, and the functionality included is comprehensive, clear and simple to use.
The key data structures of GeoPandas are the GeoSeries and the GeoDataFrame. The main difference between these GeoPandas structures and the familiar Pandas structures is the presence of a geometry column which contains the geospatial component.
At the outset I made a list of key GeoPandas skills I would need to tackle my project. These are the highlights:
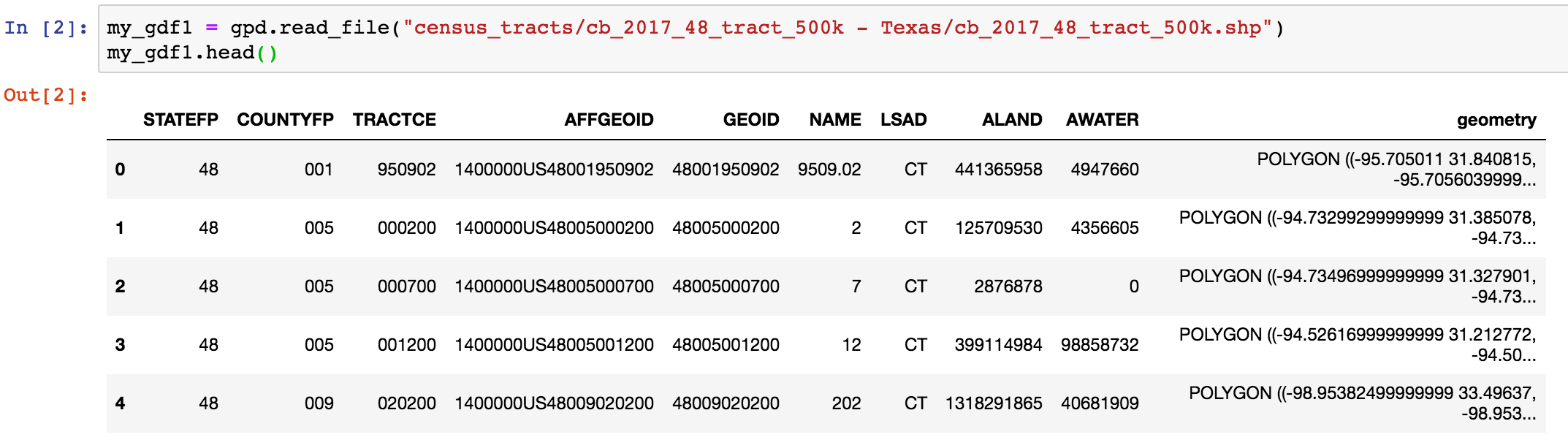
Reading in the data – gpd.read_file()
Notice the geometry column: in this case it contains polygons so we know we are dealing with shapes, rather than points or lines.
Checking the co-ordinate reference system – .crs
This attribute tells us which co-ordinate reference system the GeoDataFrame is using – for more details use http://www.spatialreference.org/ref/epsg/4269/.

Re-projecting to a new CRS – .to_crs()
This is a big part of how we will be solving our challenge, and it’s a one-liner!

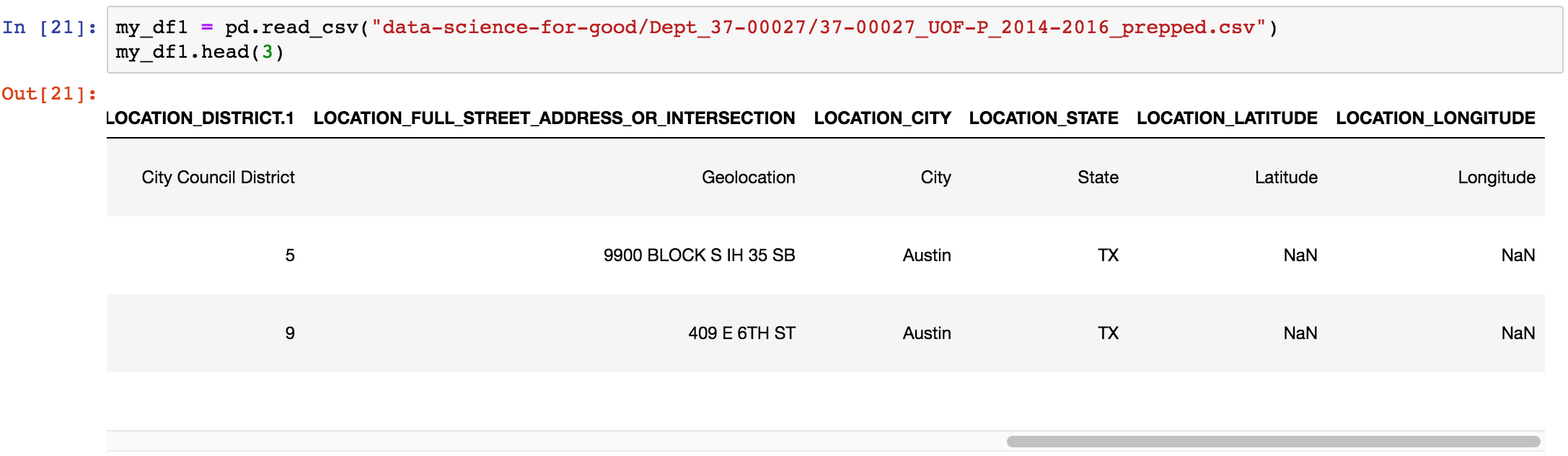
Convert a Pandas df to a GeoPandas gdf – GeoDataFrame()
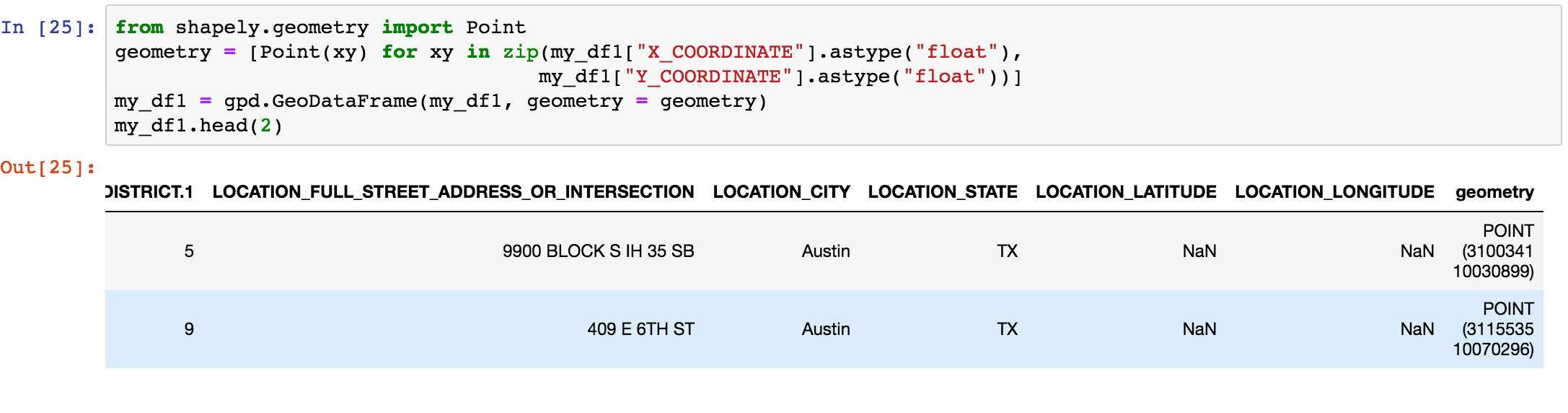
Some of our data, such as the use of force files, comes with information including x,y co-ordinates or latitude, longitude – but it is in a *.csv format. We need to convert the resulting Pandas dataframe to a GeoPandas GeoDataFrame:
We’ll use the shapely.geometry library’s Point module to help us do that – notice how the GeoPandas column geometry is added as a result:
Geocoding with Google’s API – .tools.geocode()
To do geocoding with the Google Maps API, you’ll need to register – but it’s a very simple process (and free!): you can head here to read more: https://cloud.google.com/maps-platform/. Once you’ve obtained your key, geocoding is a simple one-liner:

It’s also interesting to check which CRS Google uses so we can convert if necessary:

Measuring distance between points – .distance()
The distance between points in 2 GeoSeries:

And finally, let’s not forget actually plotting the maps! – .plot()
Drawing a basic map is deceptively simple…
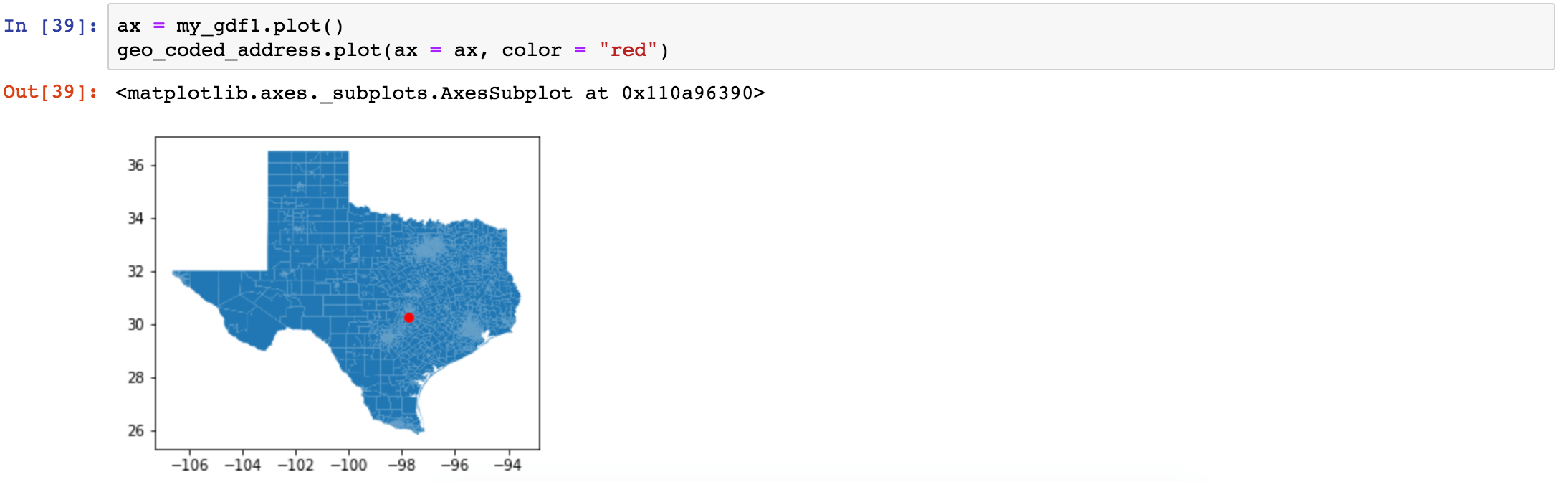
We can overlay the information from different GeoSeries or GeoDataFrames using ax:
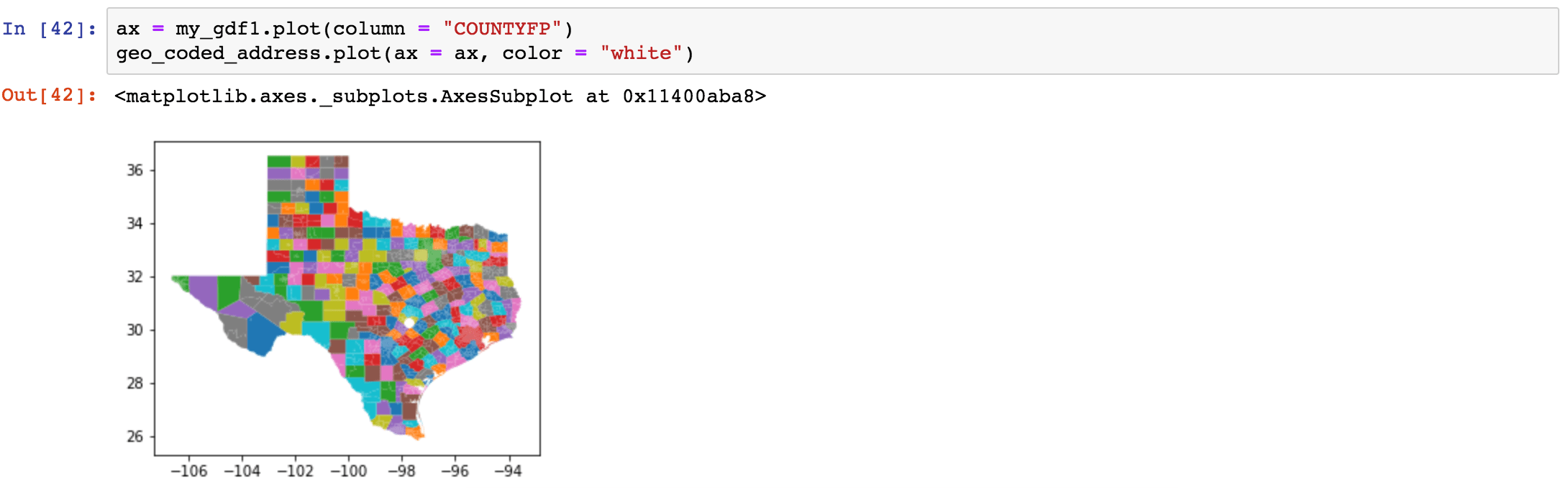
And we can colour each polygon shape according to any column values we choose – here I’ve coloured Texas by county:
Solving the geospatial challenges
I picked 2 key aspects to address:
1. How do we even know what data we have, and what broad issues will we face with the data?
2. How do we standardize co-ordinate reference systems (CRS) across census-level data and police-level data, even when the CRS is unknown?
What are we dealing with?
The folder structure for the data was a bit of a monster. On Day 1 I spent most of the day just opening folders, wondering what the numbers meant, wondering why folders had different numbers of files in them, and then laboriously opening files to inspect their contents:
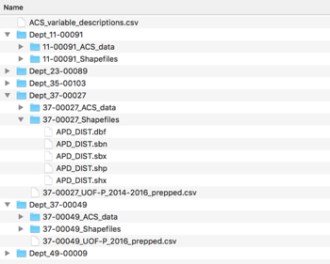
At the end of Day 1 I had understood the folder structure (fortunately consistent if a little arcane) and some of the issues with the data (not so nice or consistent) and I desperately wanted to NOT have to do this manually ever again! Remember we’ve only been given data for 6 police departments but once we have all the data for all the departments across all the states we’d absolutely have to automate this task. I wrote a function with the help of Python os which would read through the folder structure and pull out the following key information:
- What county / state combinations does each Dept file represent?
- Has a use of force (uof) file been provided or not?
- In the shapefile data are any of the 4 key files missing?
- In the ACS data were the files provided consistently for the same county?
This is what it looks like (I also got to do a bit of Pandas dataframe styling to make the bad stuff stand out in red):
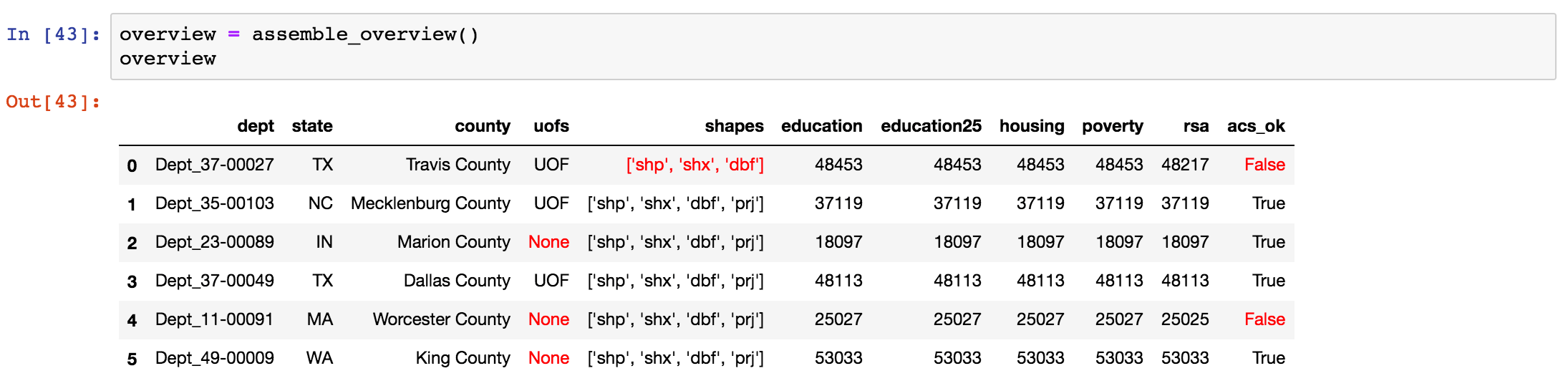
In the above output we see immediately:
- We have only been given use of force data for 3 of our 6 police departments: Travis, Mecklenburg and Dallas.
- The shapefile data from Travis is missing a “prj” file so we’re going to need to identify the correct co-ordinate reference system before we can even thinking of analysing or plotting that data further.
- And for both Travis and Worcester we have troublesome ACS data – notice that for Travis all entries are “48453”, except for rsa (race-sex-age) where we’ve been given the data for FIPS county “48217”. Similarly for Worcester the rsa data is for a different county.
The census tracts use what are known as FIPS codes (e.g. 48453) to break down the US into states and counties (e.g. 48 for Texas and 453 for Travis County). These codes are available for download and provided an easy key to read which state and county data is included in any given ACS file.
Once we have data available for all 52 states, this quick analysis will give us a good idea of where we can dive in and start working with the data, and where we need to focus on further data preparation efforts before we begin.
How do we standardize the CRS?
The American Community Survey (ACS) data is broken down into “census tracts” but the corresponding shapefiles were not supplied. Fortunately Darren Sholes supplied us with the link to get them. These shapefiles consistently use CRS = epsg:4269, so for my purposes I decided to use that as my base standard. All other data would need to be converted to this CRS.
For data where we have the CRS it’s easy, we use our .to_crs() function and convert – job done!
But for data like Travis County where we have no *.prj file and the use of force data is supplied with x,y co-ordinates rather than latitude and longitude I needed a method to determine the correct CRS to set before converting to our standard.
What I noticed about the use of force UOF data is that, although a variety of standards were used when it came to location, physical address was always supplied. It occurred to me that a simple solution would be to:
- Sample 3 random addresses from UOF file
- Geocode them using the Google API
- Convert these to our standard CRS = epsg:4269
- Then for each possible CRS projection, convert our original UOF addresses to that projection, then convert to our standard epsg:4269
- And finally compare the distance between the resulting sets of points
- The combination with the least distance between them represents the “best fit” CRS for using on our data
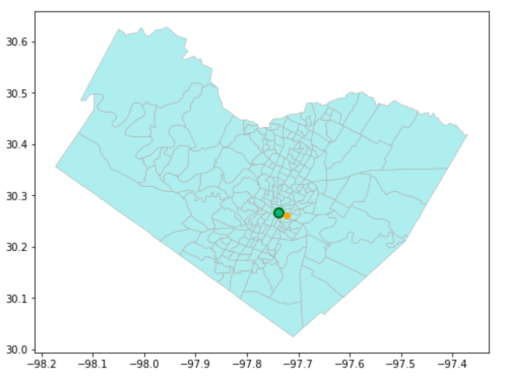
For example, if the big dark green dot is our “ground truth” address from Google, then the CRS applied to the pale green dot is clearly a better fit compared to the CRS applied to the orange dot which landed further away:
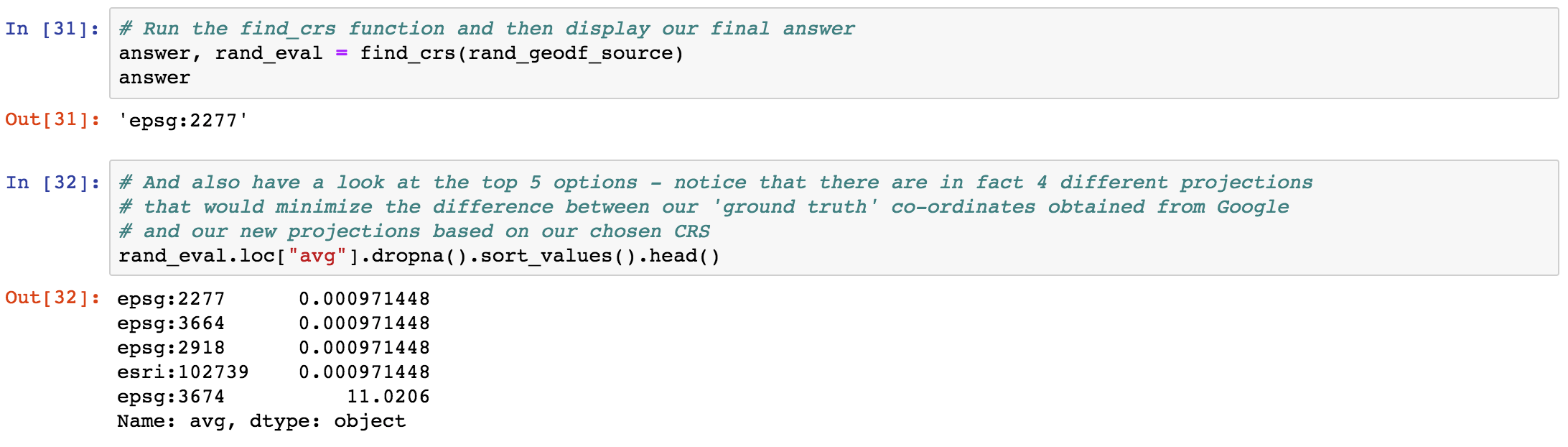
The function returns an “answer” which is what is then subsequently used to convert the data. It is also possible (and I thought quite interesting!) that there may be more than one right answer – see my Top 5 below for the Travis scenario…
The outcome
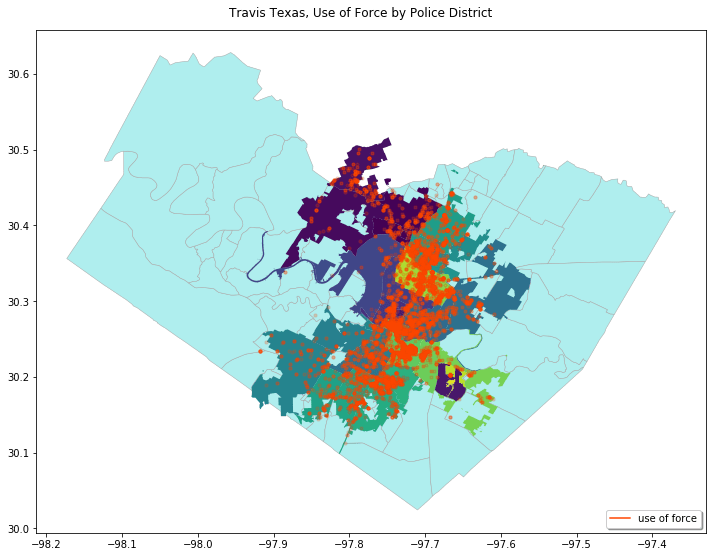
Once the data has been standardized then meaningful analysis is enabled. For example, here we see the correct map and visualization of use of force for Travis Texas has now become possible:
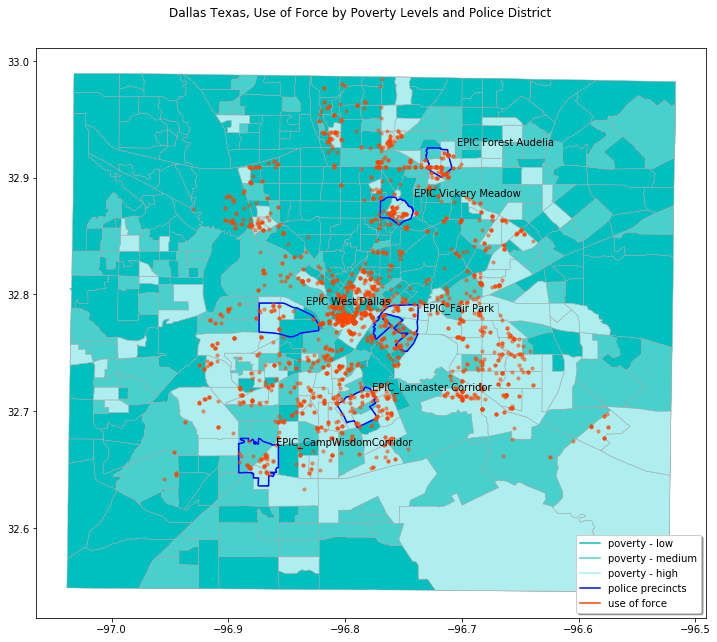
And here is another possible visualization showing use of force correlated with poverty levels for Dallas Texas: