In 2020 I completed the Udacity Deep Learning Nanodegree, which focuses on implementing a variety of deep learning architectures using PyTorch. At the outset, it’s pretty fundamental to understand the data structures you’ll be encountering as inputs to and outputs from your neural network architecture. What I noticed was that plenty of the issues encountered by me and my fellow-students arose from misunderstanding either the shape or format of the data, going in, being processed, or coming out: you need to actually have a nice mental map of how your data is transformed at each step. The accompanying Jupyter Notebook tutorial aims to cover all those basics, and assumes a good level of prior Python knowledge as well as a smattering of linear algebra but no prior knowledge of PyTorch. I hope it may help you to get up and running quickly!

These are the topics covered in the tutorial:
NumPy
- A refresher on common linear algebra data structures
- Understanding NumPy arrays with 3+ dimensions
- Populating and re-shaping arrays
Practical use-case walkthroughs
- Natural language processing – preparing word vectors
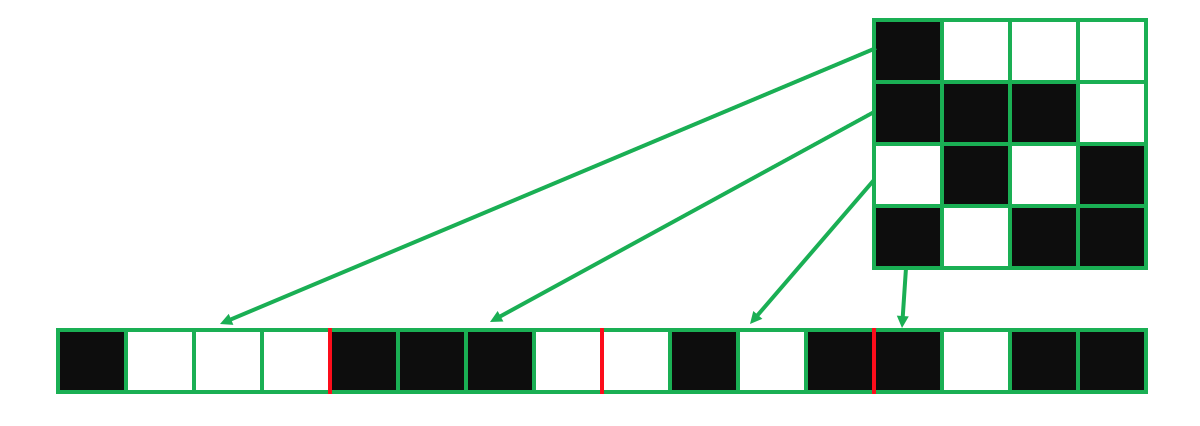
- Black & white images – preparing a matrix that represents greyscale values
- RGB images – preparing 3D data that represents 3 colour channels
- Flattening image data, ready for feeding into a neural network
Operations
- Basic math operations (+, -, *, /)
- Dot product
- Matrix product
- Matrix transposition
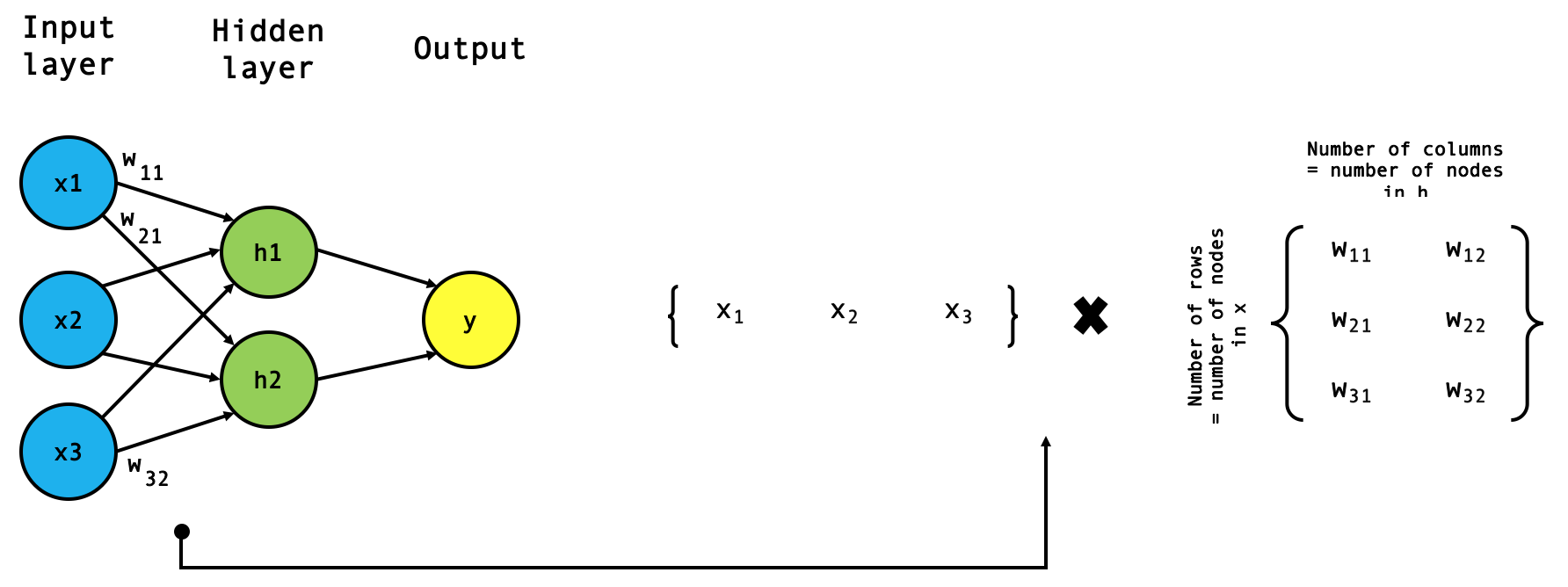
- The forward pass: matrix multiplication in action
PyTorch
- The PyTorch tensor
- Understanding tensor shapes and dimensions
- Populating and re-shaping
- Understanding data types
- Converting data types
- Operations
- Transposing
- A practical example: coding the softmax function
PyTorch to NumPy and back again
- You’ll need to convert from one to the other all the time, so this is good to know too!
And now, off to the Deep learning data structures tutorial on Github:


Comments
One response to “Data structures for deep learning”
[…] hidden layer, is therefore to find the dot product of our inputs and our weights (take note of the tensor shapes involved […]
LikeLike